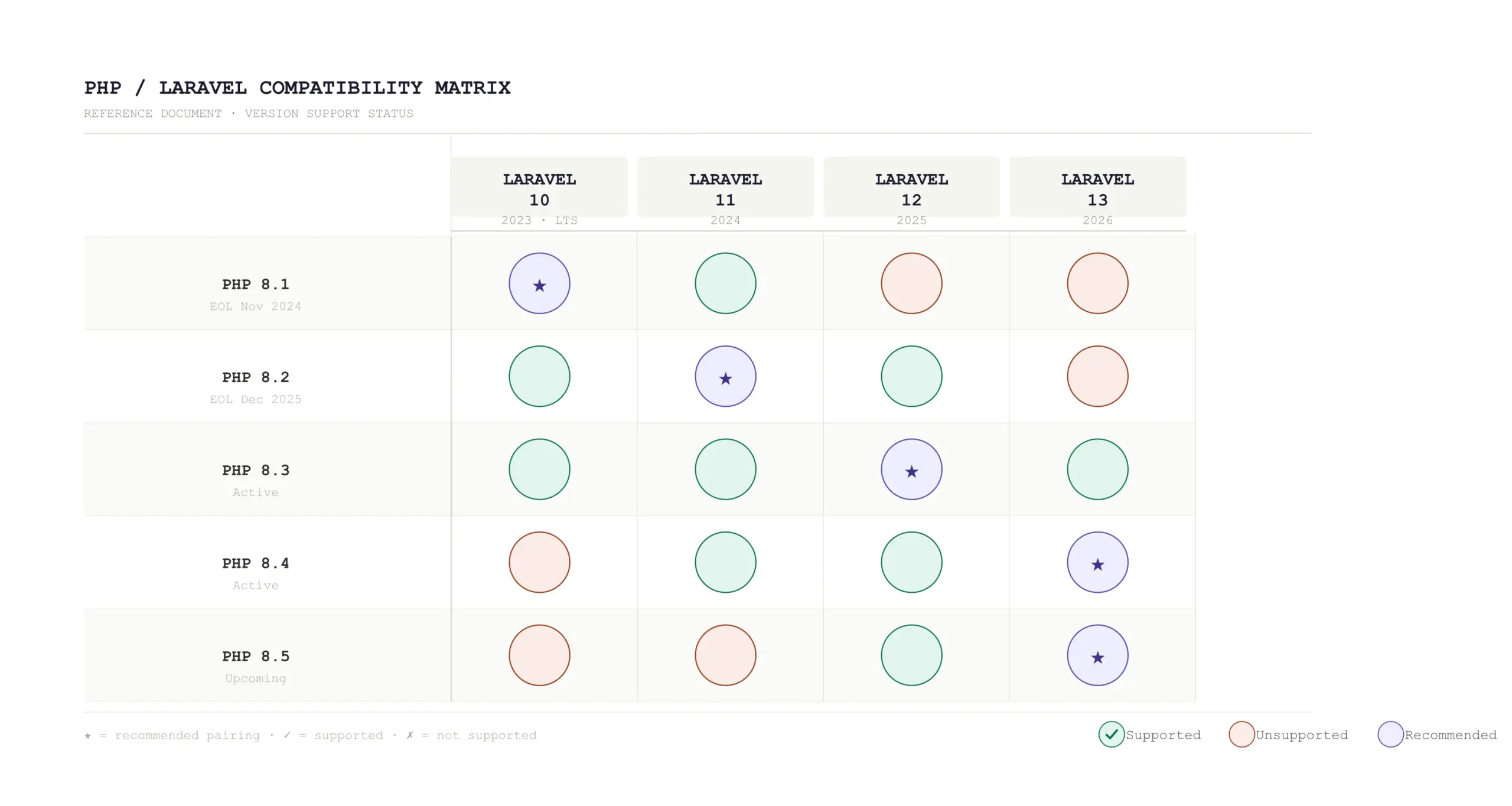
Quick reference: Laravel 13 requires PHP 8.3 minimum and supports PHP 8.3, 8.4, and 8.5. Laravel 12 requires PHP 8.2 minimum. Laravel 11 security support ended March 12, 2026. Laravel 10 is fully end-of-life. If you are setting up a new project in 2026, start on Laravel 13 with PHP 8.4.
If you are deciding whether to invest in an upgrade or start fresh, our article on whether Laravel is still the right choice in 2026 covers the business and technical case in full. For the step-by-step upgrade process from older versions, see our Laravel upgrade guide for 2026.
Updated for Laravel 13 — released March 17, 2026.
You’re setting up a new server. Or a client just asked: “Can we upgrade to Laravel 13 with our current PHP 8.1 stack?” The answer, tucked inside release notes and Composer errors, can cost your team hours. This guide puts every answer in one place — a clear, accurate laravel php compatibility reference for Laravel 10 through 13, with practical upgrade guidance for real teams.
In this article
Laravel PHP Compatibility Matrix — Quick Reference (2026)
The table below answers which php version for laravel at every major release. Check it before you touch composer.json.
| PHP Version | Laravel 10 | Laravel 11 | Laravel 12 | Laravel 13 |
|---|---|---|---|---|
| PHP 8.0 | ✗ | ✗ | ✗ | ✗ |
| PHP 8.1 | ✓ | ✗ | ✗ | ✗ |
| PHP 8.2 | ✓ | ✓ | ✓ | ✗ |
| PHP 8.3 | ✓ | ✓ | ★ Best | ★ Min |
| PHP 8.4 | ~ | ~ | ✓ | ★ Rec |
Legend: ★ = Recommended • ✓ = Supported • ✗ = Not supported • ~ = May work, not officially tested
A note on Laravel 13.3+ and PHP 8.3
Some patch versions of Laravel 13 pull in Symfony 8 components that hard-require PHP 8.4. If you’re on PHP 8.3, stay on Laravel 12 until you can upgrade your runtime, or pin laravel/framework: ^13.0 <13.3 temporarily.
Laravel 10 — PHP Requirements
Laravel 10 dropped PHP 8.0 and made PHP 8.1 the minimum. It’s the last version to support PHP 8.1, which still matters for teams managing older hosting stacks. Laravel 10 also introduced full return types and argument types in every stub — a nice developer-experience improvement that PHP 8.1 made possible.
| PHP Version | Supported | Notes |
|---|---|---|
| PHP 8.0 | Not supported | Dropped from Laravel 10 |
| PHP 8.1 | Supported | Minimum requirement |
| PHP 8.2 | Supported | Fully compatible |
| PHP 8.3 | Supported | Compatible, though not official at release |
Laravel 10 is EOL
Security support for Laravel 10 ended in early 2025. If you’re still on Laravel 10, you’re already outside the safe support window.
Laravel 11 — PHP Requirements
Laravel 11 raised the minimum to PHP 8.2. That wasn’t just a cosmetic change. PHP 8.2 brought readonly classes, DNF types, and deprecated dynamic properties, and Laravel 11 leaned into that with its slimmer app structure.
The Laravel 11 project structure is also worth noting. It removed several default files, like the separate api.php route file and much of the starter middleware setup. Existing Laravel 10 apps do not need to mirror that new layout to upgrade safely.
| PHP Version | Supported | Notes |
|---|---|---|
| PHP 8.1 | Not supported | Minimum dropped |
| PHP 8.2 | Supported | Minimum requirement |
| PHP 8.3 | Supported | Recommended |
| PHP 8.4 | Unofficial | Community tested, not guaranteed |
Laravel 11 is now out of security support
Security support ended March 12, 2026. Any production app still running Laravel 11 should be on an active upgrade path now.
Laravel 12 — PHP Requirements
Laravel 12 was intentionally calm. The core team focused on minimizing breaking changes instead of introducing large new APIs. In practice, many applications move from Laravel 11 to Laravel 12 without touching application code. It also introduced updated starter kits and optional WorkOS AuthKit integration for passkeys and SSO.
For laravel 12 php compatibility, Laravel 12 requires PHP 8.2 as the minimum, while PHP 8.3 and 8.4 both work comfortably. In 2026, PHP 8.3 remains the safest general recommendation for most Laravel 12 production environments.
| PHP Version | Supported | Composer Constraint |
|---|---|---|
| PHP 8.1 | Not supported | — |
| PHP 8.2 | Supported | ^12.0 |
| PHP 8.3 | Recommended | ^12.0 |
| PHP 8.4 | Supported | ^12.0 |
// composer.json
{
"require": {
"php": "^8.2",
"laravel/framework": "^12.0"
}
}Laravel 12 support timeline
Bug fixes continue until August 13, 2026. Security fixes continue until February 24, 2027. If you are on Laravel 12 today, you still have time — but Laravel 13 should already be part of your plan.
Laravel 13 — PHP Requirements (Released March 2026)
Laravel 13 launched on March 17, 2026. It is the current recommended version for new applications, and the biggest practical shift is straightforward: laravel 13 php version raises the minimum to PHP 8.3 and drops PHP 8.2 entirely.
Zero breaking changes from Laravel 12 to 13
If you’re already on PHP 8.3 and Laravel 12, the upgrade is one of the lightest major-version moves Laravel has had.
What’s new in Laravel 13 that leans on PHP 8.3?
- Native PHP Attributes across more framework locations
- Laravel AI SDK with a provider-agnostic approach
- Cache::touch() to extend TTL without refetching data
- Reverb database driver for WebSocket broadcasting without Redis
- Passkey authentication in the auth scaffolding
| PHP Version | Laravel 13 Support | Recommendation |
|---|---|---|
| PHP 8.2 | Not supported | Upgrade PHP first |
| PHP 8.3 | Supported (Min) | Works for 13.0–13.2 |
| PHP 8.4 | Recommended | Best for 13.3+ and beyond |
Laravel 13.3+ practical reality
Because of Symfony 8 dependencies, Laravel 13.3+ can effectively require PHP 8.4 in practice, even though Laravel 13 officially lists PHP 8.3 as the minimum.
// composer.json
{
"require": {
"php": "^8.3",
"laravel/framework": "^13.0",
"phpunit/phpunit": "^12.0"
}
}Support Status & End-of-Life Dates (2026)
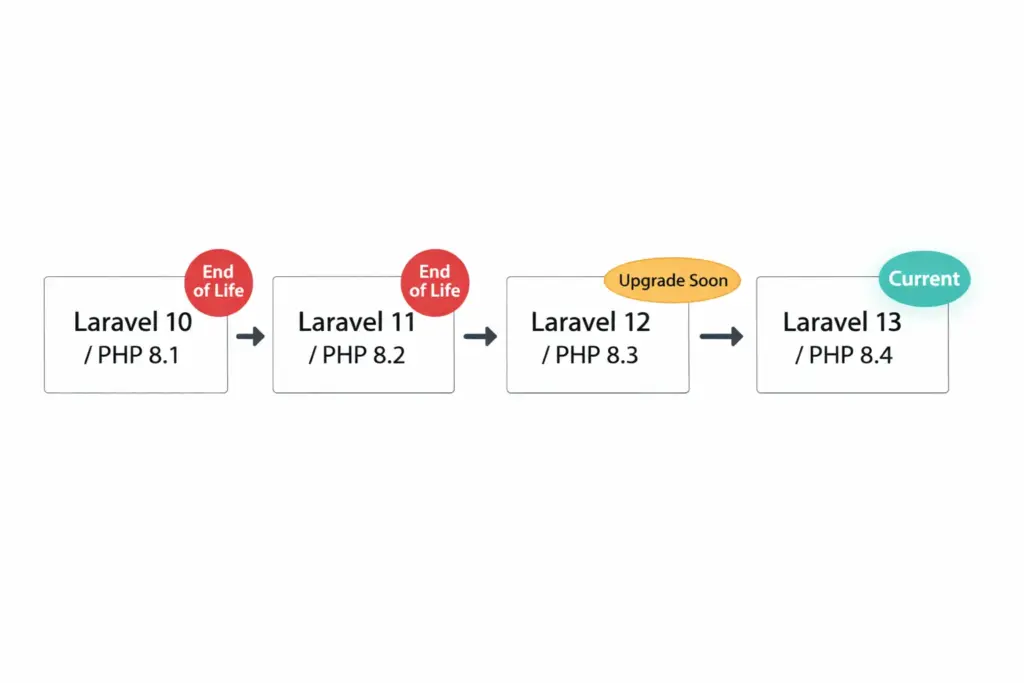
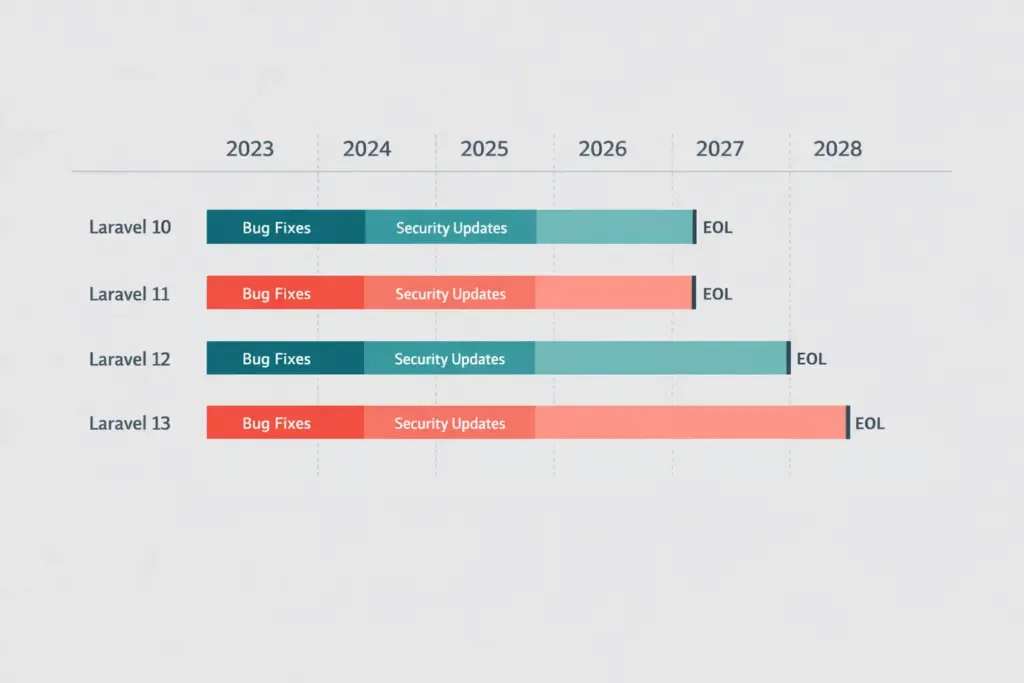
Laravel’s support policy provides bug fixes for 18 months and security fixes for 2 years per major release. Here’s the picture as of April 2026:
Laravel 10
End of Life
Bug fixes ended Aug 2024
Security ended Feb 2025
Min PHP 8.1
Laravel 11
End of Life
Security ended Mar 12, 2026
Migrate urgently
Min PHP 8.2
Laravel 12
Active Support
Bug fixes Aug 13, 2026
Security Feb 24, 2027
Min PHP 8.2
Laravel 13
Current
Bug fixes Q3 2027
Security Q1 2028
Min PHP 8.3
No LTS in Laravel (since v6)
Laravel 6 was the last LTS release. Every current major version follows the same 18-month bug-fix and 2-year security model, which makes steady annual upgrades the healthier habit.
Upgrade Path & Pre-Flight Checklist
You cannot skip major versions cleanly in Laravel. The upgrade path should be sequential:
Laravel 10 → Laravel 11 → Laravel 12 → Laravel 13
Pre-upgrade checklist: Laravel 12 → 13
- Run
php -von production. You need PHP 8.3 minimum, and PHP 8.4 for Laravel 13.3+. - Update
composer.jsonto requirelaravel/framework: ^13.0andphpunit/phpunit: ^12.0. - Run
composer updateon a feature branch. - Clear caches before testing the app.
- Review queue behavior, cache configuration, and CSRF/origin settings.
- Drain queues before deployment if you are moving workers between Laravel 12 and 13.
- Deploy to staging first and run the full test suite.
- Confirm ecosystem packages like Livewire, Inertia, Filament, and Spatie packages are ready.
Use Laravel Shift for mechanical upgrades
For larger apps, Laravel Shift is often worth it because it handles much of the repetitive upgrade work and opens a reviewable pull request.
What if I’m still on PHP 8.1?
If your server still runs PHP 8.1, you are locked to Laravel 10 — which is already end-of-life. The safest route is usually PHP 8.1 → PHP 8.2 first, then Laravel 11 or 12, then PHP 8.3, and finally Laravel 13.
Summary: Laravel PHP Compatibility at a Glance
Legacy
- Laravel 10 — Min PHP 8.1 • EOL
- Laravel 11 — Min PHP 8.2 • Security ended Mar 2026
Current
- Laravel 12 — Min PHP 8.2 • Best on 8.3
- Laravel 13 — Min PHP 8.3 • Best on 8.4
Practical Rule
- No LTS exists now
- Upgrade sequentially
- Check PHP first, then Laravel
The laravel php compatibility story in 2026 is actually encouraging. The upgrade from Laravel 12 to Laravel 13 is one of the smoothest Laravel has had. For most teams, the real blocker is not application code. It is the PHP version running underneath the app.
Tags: #Laravel #PHP #Laravel13 #PHP83 #WebDevelopment #ITMarkerz